





The current state concept has been very popular since SQL databases came along. It simply says that every object is persisted in the database in its current state. This model seems to be the most natural for developers, since they’re meeting it from the very beginning of their programmers’ experience.
But this model also brings some limitations. Have you ever been in a situation when your data turns out to be insufficient? Or in a situation when you wish you had a full history of actions that happened in your application, but you don’t? These are very common problems when you develop applications based on current state. Of course, you can always implement a mechanism that keeps historic data and read from it. However, this is rather a workaround, not a complete solution. A complete, best solution in such situations is to use the event sourcing model.
The domain events
Event sourcing forces you to switch your mindset, and stop thinking of your application as a database-centric unit, where the data structure is the most important. You should start focusing on actions that happen in your application. These actions are called the domain events. The domain event is a fact that happened in the past, some state transition. The domain event is the main and only source of information in your application, so you should spend some time on designing proper events describing your application’s domain. This is called event storming, and that’s probably the most important stage during the design phase.
To understand this article better, let’s imagine you have to design a simple blog, with just a few use cases:
- blog owner can add posts
- blog owner can update posts
- blog readers can add comments to the posts
In this article I will put some code examples that are part of a sample application available on my GitHub account: https://github.com/ulff/phpcon-demo
So you see you need three domain events to provide these features. There is an event naming convention, which says you should use verbs, and use past tense, since events are facts that occurred in the past. Your events should be called that way then:
- PostWasPublished
- PostWasUpdated
- CommentWasAdded
First one of that list should provide with few details like post title, post content, and publishing date. It could look like that:
class PostWasPublished implements DomainEvent
{
private $postId;
private $title;
private $content;
private $publishingDate;
public function __construct(
PostId $postId,
$title,
$content,
\DateTime $publishingDate
)
{
$this->postId = $postId;
$this->title = $title;
$this->content = $content;
$this->publishingDate = $publishingDate;
}
// ...
}
The domain events should be persisted, so they are usually saved in the persistence layer called event storage. Event storage is a database that keeps all events. What is most important, that database is append-only. You should neither ever delete nor update state of the events saved there. That is strictly forbidden in an event sourced application. When you are preparing an event to be saved in the event storage, you should create a stored event. A stored event is a structure that keeps domain event data along with some metadata around it, like event type, event aggregate identifier or event recording date.
The aggregates
Aggregate is another keyword in the event sourcing. The aggregate is an object that is affected by a stream of events. In simple words you can think of it as of a document or entity in the database. Referring it to your blog application, Post is one of your aggregates. Every Post object is created and modified by PostWasPublished and PostWasUpdated events.
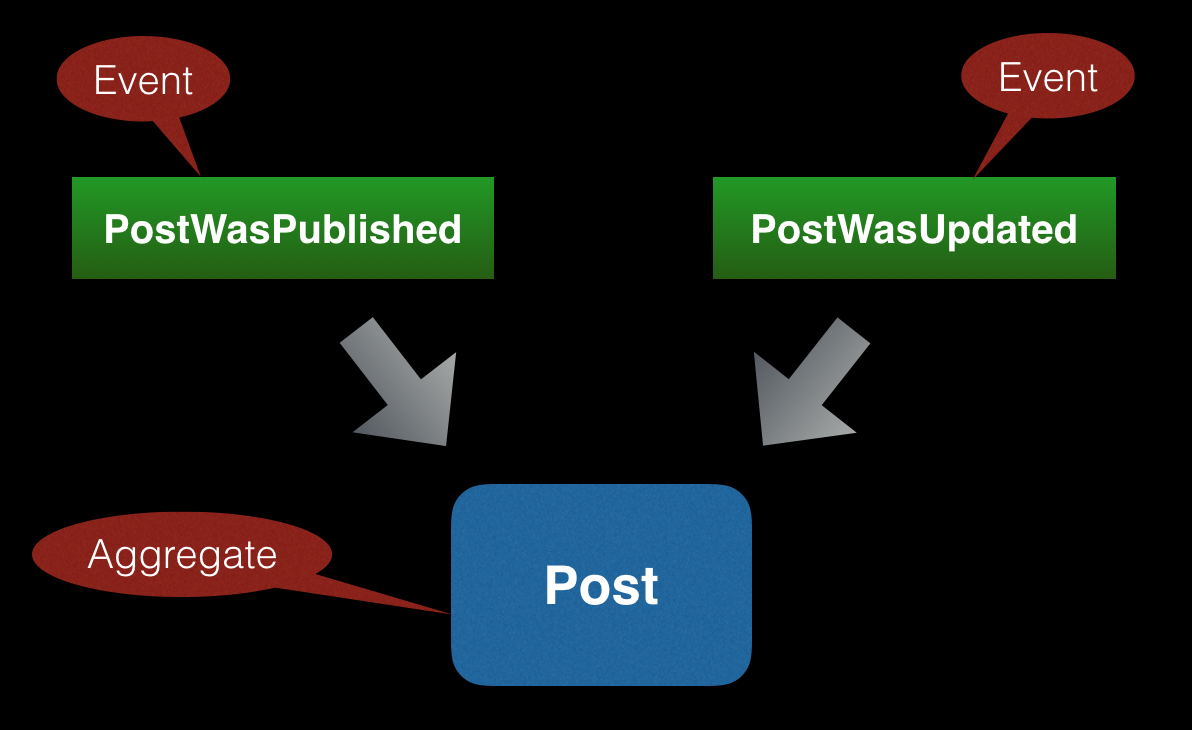
You should define an interface for aggregates that will provide with few methods:
interface Aggregate
{
/**
* @return DomainEvent[]
*/
public function getEvents();
/**
* @return AggregateId
*/
public function getAggregateId();
/**
* @return Aggregate
*/
public static function reconstituteFrom(
AggregateHistory $aggregateHistory
);
}
Method getEvents() returns a set of recorded events affecting aggregate’s state. Method getAggregateId() returns an identifier of the aggregate. Aggregate identifiers are defined in aggregates and in domain events. Aggregate identifier in domain event object keeps information which aggregate is affected by that event. If you take a look back on PostWasPublished code, you will see a PostId object which is an implementation of AggregateId interface. It simply says which Post is affected by that event.
Last static method reconstituteFrom() allows reconstituting the state of the aggregate on the basis of the events from the past. Sample implementation of that method for Post aggregate could look that like:
class Post implements Aggregate
{
public function __construct(PostId $postId)
{
$this->postId = $postId;
}
// ...
public static function reconstituteFrom(PostAggregateHistory $aggregateHistory)
{
$post = new self($aggregateHistory->getAggregateId());
foreach ($aggregateHistory->getEvents() as $event) {
$applyMethod = explode('\\', get_class($event));
$applyMethod = 'apply' . end($applyMethod);
$post->$applyMethod($event);
}
return $post;
}
}
PostAggregateHistory object passed there is a simple structure wrapping up aggregate identifier and a set of all events affecting that aggregate. The method goes through all these events and runs methods applying events on Post object. Implementation of the methods applying events is visible below:
class Post implements Aggregate
{
// ...
private function applyPostWasPublished(PostWasPublished $event)
{
$this->setTitle($event->getTitle());
$this->setContent($event->getContent());
$this->setPublishingDate($event->getPublishingDate());
}
private function applyPostWasUpdated(PostWasUpdated $event)
{
$this->setTitle($event->getTitle());
$this->setContent($event->getContent());
}
// ...
}
You see the point of this method is to transform Post object with changes defined in the events.
State reconstitution is vital for processing commands and generating further events. Reconstituted object should never be saved anywhere, it should be processed and removed by the garbage collector.
Processing aggregates
Now, let’s assume you want to implement a use case, which allows to update Post state. You define a business logic of that use case:
// class Domain\UseCase\UpdatePost
public function execute(Command $command, Responder $responder)
{
$postAggregateHistory = new PostAggregateHistory(
$command->getPostId(),
$this->eventStorage
);
$post = Post::reconstituteFrom($postAggregateHistory);
$post->update(
$command->getTitle(),
$command->getContent()
);
try {
$this->eventBus->dispatch($post->getEvents());
$this->eventStorage->add($post);
} catch(\Exception $e) {
$responder->postUpdatingFailed($e);
}
$responder->postUpdatedSuccessfully($post);
}
At first point, you get the stream of events for desired Post and reconstitute its current state. Then, you call the update() method on it, passing command parameters; new title and content for Post. The update method must not simply change Post’s state – it should record new event saying the Post was updated and apply it:
class Post implements Aggregate
{
use EventSourced;
// ...
public function update($title, $content)
{
$this->recordThat($event = new PostWasUpdated(
$this->getAggregateId(),
$title,
$content
));
$this->apply($event);
}
private function applyPostWasUpdated(PostWasUpdated $event)
{
$this->setTitle($event->getTitle());
$this->setContent($event->getContent());
}
// ...
}
Methods apply() and recordThat() are provided by used EventSourced trait (see the details in the sources on my GitHub). Now, getting back to the update use case – after calling update() on Post you save recorded events and dispatch them using EventBus. Note that state of Post was not saved anywhere.
Dispatching events
All recorded events should be saved in the event storage and dispatched in the application, so any interested domain event listeners could process them. Event dispatching is made by the EventBus. A very simple implementation of the EventBus could look like that:
class EventBus
{
private $listeners = [];
public function registerListener(DomainEventListener $domainEventListener)
{
$this->listeners[] = $domainEventListener;
}
public function dispatch(array $events)
{
foreach ($events as $event) {
foreach ($this->listeners as $listener) {
$listener->when($event);
}
}
}
}
It allows registering a new listener in the constructor and it keeps all registered listeners in the local array. The dispatching method takes recorded events (normally one, sometimes few) and goes through all registered listeners, calling method when() on them. That means all of your domain event listeners should provide with such method:
interface DomainEventListener
{
/**
* @param DomainEvent $event
*/
public function when(DomainEvent $event);
}
Implementation of that method should check if specific listener is interested in using given event. You could create a base class for all of your listeners, since all of them will have a common part of logic:
abstract class AbstractDomainEventListener implements DomainEventListener
{
protected $projectionStorage;
public function __construct(EventBus $eventBus, ProjectionStorage $projectionStorage)
{
$eventBus->registerListener($this);
$this->projectionStorage = $projectionStorage;
}
public function when(DomainEvent $event)
{
$method = explode('\\', get_class($event));
$method = 'on' . end($method);
if (method_exists($this, $method)) {
$this->$method($event);
}
}
}
In the constructor you can see every instantiated listener should register itself in the EventBus. Also note that you pass a ProjectionStorage as a dependency there. What is that? This is a part of read model, which is a very strong point of event sourced applications.
Read model and projections
Read model in event sourcing is based on projections. Projecting is a process of converting (or aggregating) a stream of events into a structural representation – persistent read model. In simple words, projections are data stored in such a way they can be easily fetched and displayed for reading purposes. They have a very simple structure. And also they are updated by every event affecting any of their data. Projections are persisted, normally in the database, but you can also use a filesystem or even a cache to store them. That is because all projections can always be cleared and replayed from the event stream. Imagine that! Anything you keep in your read model, can be deleted and replayed again!
Projections are the strength of an event sourced application because they are extremely fast to load. That means they are heavily improving application’s read performance.
Getting back to your sample blog application – let’s assume you want to create a projection for displaying posts list. The list will contain only a blog title and publication date. So you define a projection for that:
class PostListProjection implements Projection
{
const PROJECTION_NAME = 'post-list';
private $postId;
public $title;
public $publishingDate;
public function __construct(PostId $postId, $title, \DateTime $publishingDate)
{
$this->postId = $postId;
$this->title = $title;
$this->publishingDate = $publishingDate;
}
// ...
}
Passed PostId is also vital here – it refers to proper Post on the list.
Remember the event dispatching idea? In your base AbstractDomainEventListener class you had defined a method when(DomainEvent $event) which is checking if your specific listener is interested in the passed event. So the listener for PostListProjection should be interested in two types of events – PostWasPublished and PostWasUpdated:
class PostListListener extends AbstractDomainEventListener implements DomainEventListener
{
public function onPostWasPublished(PostWasPublished $event)
{
$postListProjection = new PostListProjection(
$event->getAggregateId(),
$event->getTitle(),
$event->getPublishingDate()
);
$this->projectionStorage->save($postListProjection);
}
public function onPostWasUpdated(PostWasUpdated $event)
{
$postListProjection = $this->projectionStorage->findById(
'post-list',
$event->getAggregateId()
);
$postListProjection->title = $event->getTitle();
$this->projectionStorage->save($postListProjection);
}
}
On PostWasPublished event you create a new item in the projection storage. It keeps title and date. On PostWasUpdated event you look for existing record and update only the title, since the publication date stays the same – it was not affected by that event.
Event sourcing and CQRS
As you see you have created a completely separate model for reading purposes. So you have just created an application that is meeting main assumption of CQRS postulate. CQRS is an abbreviation for Command Query Responsibility Segregation. It says that you should use a different model to process commands that update the state of your application, and different for queries that only get information without changing anything. Greg Young, the initiator of CQRS postulate, said once: You can use CQRS without event sourcing, but with event sourcing you must use CQRS.
Following picture shows the idea of CQRS and it is probably the most important thing you should remember from this article because it shows the whole idea of event sourced application:
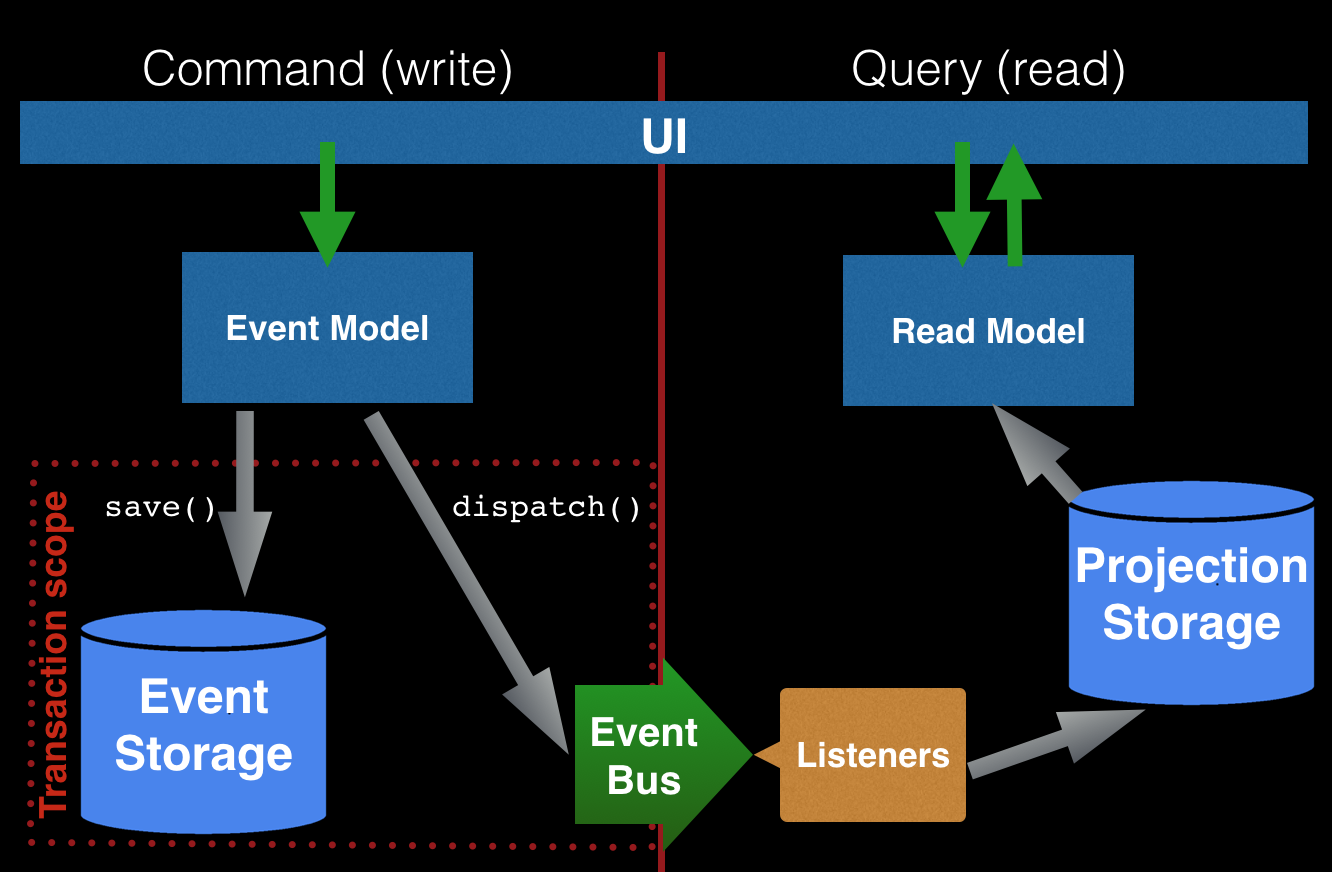
Snapshots
When telling someone the idea of reconstituting an object state from history of all its events, I always hear doubts: Really?! It must kill application’s performance! There can be thousands of events. Well, in general, event sourced applications normally deal with thousands of events, but if it still worries you – you can always use snapshots.
A snapshot is a mechanism that allows reconstituting an aggregate from non zero state. You can avoid processing large number of events with it. Normally you reconstitute the state of event like that:

But you can always pick one of these events, e.g. n+3, and say it will be a snapshot. Then, the process of reconstituting the state will start from that snapshot:

That way you simply avoided processing n+3 events every time. Nevertheless, you can always skip this snapshot and you still have the whole event history. If you prefer to instantiate an object in a historic state, before the snapshot, you can simply skip it. You can also define snapshots regularly. For example you can set up a mechanism that will set a snapshot every month. Whenever you need an object state from the past, you go back through the event stream and skip as many snapshots as you find to be matching your expectations, so the one with the date not later that you need.
But… why?!
Now, when you know the basics of the event sourcing model, you could wonder – why should I even care about it? Should I use it? When should I use it? What does it offer?
I do not say event sourcing is always better. But this is a different way of modelling. In my opinion, it really simplifies modelling. It lets you focus on actions and it allows you to have a better overview of your application. And this is just the beginning.
Event sourcing makes your application more real-life like. As a human being you always see and understand the world as a set of actions. Event sourcing model is used in many areas in current world. For example this is how bookkeeping works. When an accountant makes some operation by mistake, he or she never corrects anything. They always make an operation rolling back the state, and then correct operation. That is like in event sourcing. Thanks to that you always have a full history. Moreover, that way you avoid all situations when you deleted something that you thought was obsolete but later turned out to be important.
This keeping-whole-history is a strong point of event sourced application. This is a key feature for every application based on the historic data. Can you imagine that you call your bank’s call centre and ask why do you have the balance of 100$ instead expected 150$, and you hear: Sorry, the database says you have only 100$, we cannot help you? Banking applications are always event sourced, and your account balance is not the sum of a column value, but a result of a set of previous operations. This is how every mature application works. Banking, insurance, bookkeeping, finance.
I used to work in a company that was developing applications for learning. We didn’t use event sourcing. And I remember many situations where we had to investigate what caused that a particular student has invalid result. That was often hard to find out. I wish we had an event sourced application then. We could know everything.
Event sourcing allows you to get back to any point in time, what’s more – it allows you to analyze and compare data from any period of time. Imagine that you are developing an internet shop application and your manager comes to you and asks: I suspect blue jackets are not trendy this season. Please check how many blue jackets we have sold this season and how many we sold during the previous one. When you have an event sourced application, you create a new projection and run it, for the current and previous seasons. And you have the result. If not – it is possible you lost this data. So you implement a new feature in your application and tell your manager: Now, we should wait till the next year, and we will have the results. Good luck, I only guess what happens then.