




The search for the ultimate folder structure for a given project can be compared to the search for the holy grail. It does not matter if it is a frontend app written with React, Go CLI tool, or a project of UI design. At the start, you will always face the question of how you should structure it. Why are we doing it? Because we want our projects to be flexible, extensible, self-explanatory, and easy to maintain. It provides a seamless developer experience for engineers working on that project.
When we grab a new tool, we start by reading “getting started”, and then we check the documentation and search for examples on GitHub. We built a “hello world” to get our hands dirty. We often use that initial project structure as a foundation for your complex real-life project. After some time, we reach a dead-end… and the maintenance of it is a nightmare. There is nothing wrong with this approach but we need to remember that those resources are just a show-off of the capabilities and functionalities of a given tool. Use it as an inspiration and always think about how to use them in the context of your problem. Today, I present you with a proven solution that should cover all of your requirements and special cases. Maybe not all of you will need this, so just pick those ideas which you like. I assume that you are familiar with Terraform and AWS, so I will not dive deep into all the details.
Here (https://github.com/MarcinKasprowicz/ultimate-terraform-folder-structure) is the link to GitHub repository where you will find the proposed structure. I encourage you to get your hands dirty and explore it before reading further.
Requirements
Let’s review what use cases the proposed structure will cover:
- AWS as a cloud provider. This could also be applied to others as Terraform supports many different providers.
- AWS multi-account setup. One account for production workloads and one for testing purposes.
- Crucial resources (e.g. database) deployed manually and on-demand.
- Short-lived dynamic environments to support review apps for branches.
- Sharing and referencing resources created by other Terraform configuration.
- Frictionless local development.
- Ability to deploy from a local machine without a complex authentication flow.
- Acting in the context of a given AWS account by assuming a role.
- Terraform states stored on a separate utility AWS account.
Context
The diagram of the infrastructure managed by the repository is shown below. As aforementioned, we have two AWS accounts on which our infrastructure operates. You are probably familiar with such a setup as it is quite typical. There is some kind of topic that broadcasts events which can then be consumed by many queues and then processed by an app. The result of it needs to be stored in persistent storage, which is in our case a DynamoDB table.
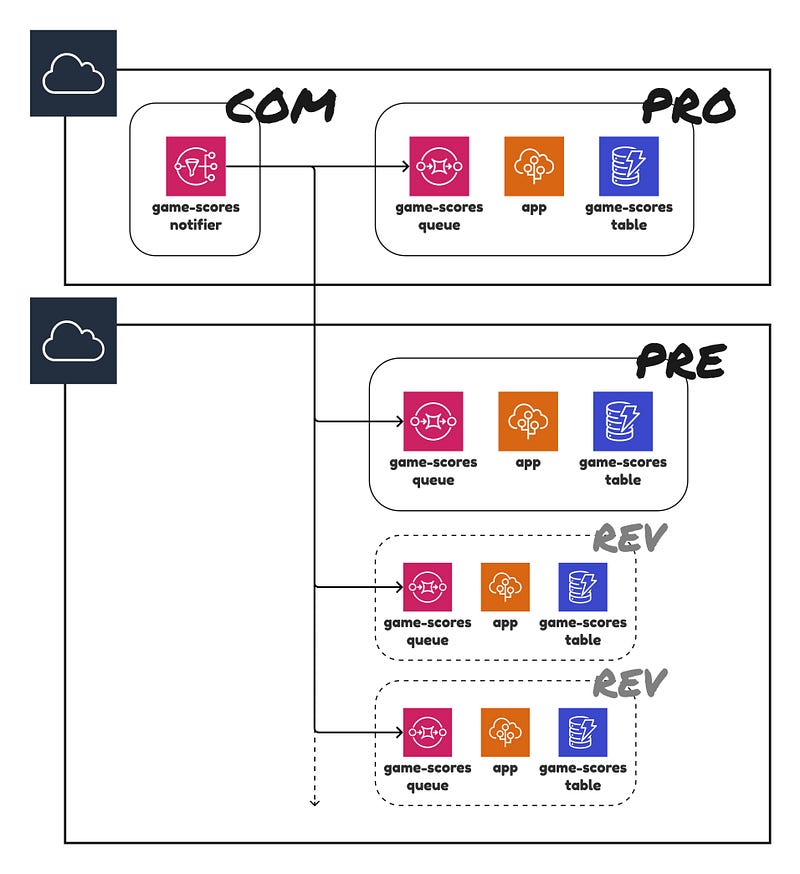
Resources are assigned to a given environment:
- com (common). Set of components shared by many. In the example, we have an AWS SNS topic called
game-scorethat can have plenty of consumers. - pro (production)
- pre (pre-production/staging). An environment for testing purposes. Acts as a gate before the production. Mirrors the production environment.
- rev (review). Dynamic short-lived environments. Spin up on demand. We can have many of them. Mimics the pre-production environment.
The proposed structure
.
├── infrastructure
│ ├── environments
│ │ ├── com
│ │ ├── pre
│ │ ├── pro
│ │ │ ├── config.tf
│ │ │ ├── db
│ │ │ │ ├── config.tf
│ │ │ │ ├── main.tf
│ │ │ │ ├── outputs.tf
│ │ │ │ └── variables.tf
│ │ │ ├── main.tf
│ │ │ ├── outputs.tf
│ │ │ └── variables.tf
│ │ └── rev
│ └── modules
│ ├── app
│ │ ├── main.tf
│ │ ├── outputs.tf
│ │ └── variables.tf
│ ├── db
│ └── queue
├── package.json
└── src
└── index.js
Before we start to break the idea down into prime factors, let’s check how simple and explicit it is to deploy on pre and pro from a local machine.
$ cd infrastructure/environments/pre $ terraform init $ terraform apply $ cd ../../../infrastructure/environments/pro $ terraform init $ terraform apply
This works for quite complex systems as we use it across our project. I found this ease of deployment (and reverting if something went wrong) to be very pleasant 😊.
Let’s analyze the folder structure and go from the top.
. ├── infrastructure # Terraform configurations └── src # An app code
This is pretty straightforward. In one directory, we keep things related to infrastructure and, in the second one, we keep an app code.
The essence
Going deeper into the infrastructure folder, you will find environments and modules. Inside environment, we have a separate directory for each environment. In modules, you will find Terraform modules imported by at least two environments (DRY 😉).
.
└── infrastructure
├── environments
│ ├── com
│ ├── pre
│ ├── pro
│ └── rev
└── modules
This is the essence of this approach and the thing that defines why this approach is so great. You could be tempted to use a configuration-driven approach where you have one Terraform configuration, but depending on the input, it generates different results. If you have three similar environments (pre, pro, rev), why not create one Terraform module and control it with a configuration stored in a json file? This idea can be influenced by the config chapter from the Twelve-Factor App methodology, but it relates to an app code (environment-agnostic), not an infrastructure code (it basically describes environments). This is what the deployment of pre environment could look like.
$ terraform apply -var-file="pre.tfvars.json"
If you would use a configuration-driven approach, you will sooner or later end up with many conditional statements and other bizarre hacks. Terraform is a tool intended to create declarative descriptions of your infrastructure, so please do not introduce imperativeness. By preparing separate Terraform modules for each environment, we see things how they look in reality. We have a direct, explicit mapping between code and a Terraform state. We limit WTFs/minute. The proposed solution will have more lines of code but still leave space for code reuse. Don’t forget about modules!
“Any fool can write code that a computer can understand. Good programmers write code that humans can understand.” — by Martin Fowler
Just one remark about workspaces. Don’t use it for differentiating environments. Even the authors don’t recommend that. Later on, I will present a good use case for workspaces.
Supplementary AWS account
How is it possible that I don’t need to reauthenticate (or change a value of AWS_PROFILE) when I am switching a context of AWS accounts?
$ cd infrastructure/environments/pre $ terraform apply # Resources deployed on test AWS account $ cd ../../../infrastructure/environments/pro $ terraform apply # Resources deployed on production AWS account # And it just works
In config.tf of any root module, you will find the following part:
provider "aws" {
# ...
assume_role {
role_arn = "arn:aws:iam::${var.aws_account_id}:role/AssumableAdmin"
}
# ...
}
This part is responsible for assuming a role. This approach is described in Terraform’s guide Use AssumeRole to Provision AWS Resources Across Accounts. The idea of assuming is pretty simple. It allows AWS account A to act in the context of AWS account B. In our case, it allows the bastion account to act in the context of production or test AWS account. What is a bastion account? I will cover it in another article in more detail. For now, you just need to know that we are using this account to centralize the management of IAM permissions, storing of state files, and locks stable. To provision with Terraform, you need an IAM user, an S3 bucket, and a DynamoDB table. You will face a chicken or the egg dilemma. We decided to move this part to a separate AWS account (bastion). It allows us (in theory) to recreate all the resources on a given AWS account just by running Terraform.
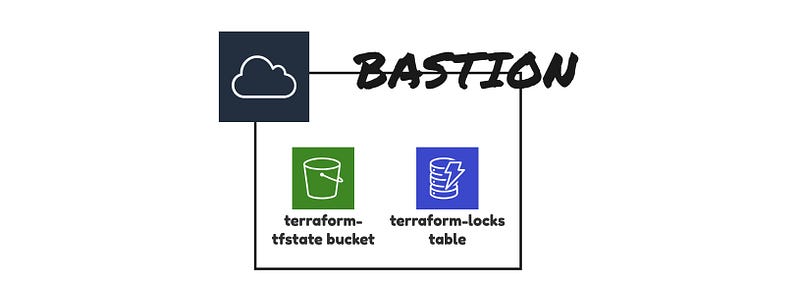
Holy Triniti… and config.tf
.
└── infrastructure
└── environments
└── pro
├── config.tf
├── main.tf
├── outputs.tf
└── variables.tf
Every root module consists of 4 files, no more, no less. Each has its clearly specified role.
config.tf. To not introduce noise at the top of themain.tffile, we decided to move the configuration of the backend and providers to a separate file.main.tf. Here, you will find definitions of all the resources managed by a module.outputs.tf. Set of module’s outputs. You can consume them further in shell scripts or reference them in the parent module.variables.tf. Set of modules inputs. For each value, we always specify the description argument for self-documenting purposes. Think of them as public class fields, whereas the values defined in the local block are private.
Porcelain components
There are some situations where you do not want to give control over your resources to automated scripts in your CI/CD pipeline. Can you think of any? Often, it is a database. Who knows what can happen when you push on master 🤷? All of us know stories where a database suddenly went down: Because an upgrade of an engine version or type of an instance has been triggered. Therefore, sometimes you would like to deploy changes on demand and from your local machine in front of the eyes of a whole team. Let’s see what that might look like in practice.
Below is our structure.
.
└── infrastructure
└── environments
└── pro
├── config.tf
├── db
│ ├── config.tf
│ ├── main.tf
│ ├── outputs.tf
│ └── variables.tf
├── main.tf
├── outputs.tf
└── variables.tf
Provisioning of pro resources using a command line.
$ cd infrastructure/environments/pro $ terraform apply # All resources except a database have been deployed $ cd db $ terraform apply # Only a database has been deployed
Dynamic environments
Have you heard about review apps? It is a strategy of deploying an app for a git branch’s lifespan. Let’s say you are working on some feature and you want to give the ability for your PM or other devs to test them before merging to master and without asking them to spin a local environment. If you have a serverless setup, it won’t cost you almost anything as you pay for usage, not for deployed resources per se. In the repository, you will find a .travis.yml file where you can find how to apply this strategy. The idea is simple. For each commit on the feature branch, you provision an environment that mirrors the pre environment. This is the perfect use case for Terraform workspaces! From their docs:
– A common use for multiple workspaces is to create a parallel, distinct copy of a set of infrastructure in order to test a set of changes before modifying the main production infrastructure.
– Non-default workspaces are often related to feature branches in version control.
What does it look like in practice? Take a look at the main.tf file in the rev directory. We basically just import and use the pre module. As we will have many different environments on the same AWS accounts (as pre and rev environments are deployed on the test AWS account), we need to distinguish them somehow. We can tag them and append a prefix to resource names.
module "deployment" {
source = "../pre"
environment = terraform.workspace
prefix = "${terraform.workspace}-"
}
Provisioning and destroying review environments can be easily done from CLI.
$ cd infrastructure/environments/rev $ terraform init # To provision them # Review app named foo-1 $ terraform workspace new foo-1 $ terraform apply # Review app named bar-2 $ terraform workspace new bar-2 $ terraform apply # To destroy them # Review app named foo-1 $ terraform workspace select foo-1 $ terraform destroy $ terraform workspace delete foo-1 # Review app named bar-2 $ terraform workspace select bar-2 $ terraform destroy $ terraform workspace delete bar-2
Sharing and referencing
In the presented architecture, we have one topic which broadcasts events to many consumers. Consumers are in different environments. We have a common part for each of them. Sound familiar? Again, quite a common scenario for which we need to be prepared.
Where should you put such resources? On pro environment? In CI/CD, you preferably would deploy pre environment before pro. If pre has a dependency in the form of pro, it can break for a couple of minutes until the whole process of deployment finishes. This dependency is also quite hidden. To tackle this problem can create an artificial common environment, which we called com. That environment is always deployed as a first. To reference resources created by com in pre or pro, you just read the output values (do you remember the outputs.tf file?) of the com module. The values are stored in a remote state.
data "terraform_remote_state" "common" {
backend = "s3"
config = {
dynamodb_table = "terraform-locks"
bucket = "terraform-tfstate-payment"
encrypt = true
key = "infrastructure/environments/com/ultimate-terraform-folder-strucutre/common.tfstate"
region = "eu-north-1"
role_arn = "arn:aws:iam::<bastion_account_id>:role/TerraformState"
}
}
resource "aws_sns_topic_subscription" "results_updates_sqs_target" {
topic_arn = data.terraform_remote_state.common.outputs.sns_game_scores_arn
protocol = "sqs"
endpoint = aws_sqs_queue.game_scores.arn
}
Summary
All of the tips that I showed you have been battle-tested in real-case scenarios and in production environments. With them, you will be able to tame most scenarios. Use them as an inspiration to create solutions that will suit your needs.