



 There are many ways to create high-performance services – all those great ideas that everyone could agree with. But what if there’s no greenfield and there’s legacy already in place? Most of those ideas cannot be defended when they meet the work conditions and the never-ending need for an effective support of the current solution.
There are many ways to create high-performance services – all those great ideas that everyone could agree with. But what if there’s no greenfield and there’s legacy already in place? Most of those ideas cannot be defended when they meet the work conditions and the never-ending need for an effective support of the current solution.
In this article we describe how we did get our Proof of Concept up and ready. The article joins the presentation of the used performance-smart architecture with the topic of refactoring the legacy project. This is the way to ‘get there faster’ through a new API. If you find this article lacking some information – please read the articles listed on the bottom. This piece is just about our use case.
Took over legacy
Our team had the honor to take over the backend project of a login system with over 6 million of registered users.
Unfortunately, the project was already referred to as ‘bloatware’ due to the great number of features pushed into this single project. The code was obsolete: it had many multi-level dependencies, layered routing, duplicated functionalities and it wasn’t easy to test. Bootstrapping the application took too long on every request.
How did this happen? It was a typical real-life scenario: The project had not been created with scalability in mind. Instead, it was created as a small local project. The developers were always under high time pressure to handle more clients and more functionalities as the market needs were growing.
We had to agree that fixing the code ‘as it is’ without any major refactoring in a reasonable time frame was simply not possible.
With the respect of what had been achieved so far in this project (the project is working ok as it is, but scaling up is troublesome), a realistic plan for refactoring was badly needed. There was more than one instance of the project, in fact there were two enormous projects with separate clients. The idea of the merge was always somewhere in the roadmap, but eventually, it wasn’t done.
Adding a touch of realism
Insanity: doing the same thing over and over again and expecting different results
(often attributed to Albert Einstein)
We were tempted by the idea of wrapping it with another layer ‘just’ to organize the code in a better way. In such case, we would still be exposed to the future bottlenecks and complicated logic that isn’t easy to be tested at the required level.
Another approach would be to create a new shiny greenfield product aside and migrate to that solution when it is ready. In our opinion the ‘new shiny one’ would never be ready for a project like this. There would always be too many new features created in the current system and the awaited migration would end up being too risky and expensive.
Both ideas mentioned above failed heavily on getting to know the current system during the process. Refusing to dive into the legacy code is tempting, but leave us vulnerable to recreating the same mistakes and unarmed against the newly discovered bugs that need to be fixed.
We are hiring: Work for our team!
The way to go
After some study, we decided to go with Service Oriented Architecture (now called ‘microservice architecture’).
The user-related endpoints made a perfect target for a performance oriented refactoring. We decided to re-create them as a separate (micro)service REST API with the same functionality. In the future this API should become the only entry point to the user databases as an internal database abstraction layer.
Thanks to that, it will be the only project to be modified when the actual database schema/tables change. The deployment of the whole login platform will be more complex, but the deployment of one component will be much easier. We already knew that we needed more robust deployments. Assuming that functional separation works well – the fixes will hit the servers faster, as we would need to apply a fix to one component only.
As simple as that. It’s almost a crystal clear once you write something concrete down after A LOT of brainstorming back and forth.
Refactoring for performance
Refactoring for performance is so much more than just writing new code. Refactoring an important functionality (and quite clearly the majority of the performance problems is related to the crucial elements) comes with a great risk of introducing new code with new bugs instead of old ones. That’s why every team needs to find their way to test it.
Technologies chosen
We decided not to touch the existing databases as changing the technology there or even merging those databases would be a great overkill in terms of work and/or related risks.
Symfony3 was used for handling the logic code because it’s a mature project with clear versioning policies and massive popularity. PHP was a natural choice as our team has mainly PHP related experience in the backend. The framework installation was stripped to the minimum; we obviously didn’t need neither the login nor the forms.
We used only technologies well known for their high performance, such as Redis and Varnish. I don’t want to go into the details here – all the numbers could be easily found on the Internet. Varnish as a simple web cache serving responses for all repeating GET requests. Then – Redis as the fast storage for the user data and user id / database mapping. Since we have more than one database it would be good to know in advance where the requested data is.
Controlling the record’s time to live in Redis is a broad case tightly related to the project functionalities. I won’t get into that here, but remember to care about the longest possible TTL while holding only the content that is up to date.
Architecture
The architecture was built on the Amazon Web Services on two t2.medium machines – one with Varnish and the second one with all the rest.
The dotted line between Web Cache and the Code element represents a logic binding together both elements. If the request is cached in Varnish, it never reaches the Code. If not, the Code element is initialized by the http request (without any ‘knowledge’ about the Web Cache existence).

One can see that Logic is handled by a single Code element. Please do not worry about it – we can establish an API gateway in the front. Such gateway can redirect URLs requesting for different endpoints to different Code elements written properly in any modern technology.
The interaction flow that covers all of the elements are presented in the architecture above.

Performance
…is a must here. Therefore, we created a proof of concept on one endpoint and ran a couple of tests using Siege. The result and an extremely brief comparison are put below.
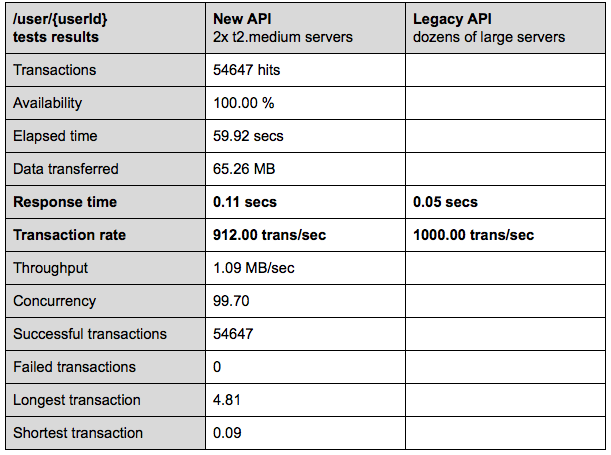
Please notice that we’re NOT comparing apples with apples – the legacy code was tested using a different tool and there was a slightly different traffic profile.
Tomorrow never dies
The conclusion is that our new API, is fast but we cannot say how much faster it would be on the similar environments in comparison to the API provided by the legacy. The machine power was many times greater during the tests run against the legacy project, but let us be aware that the new API was only a single endpoint implementation and probably will stay codependent to the legacy code for some time.
I hope that we will be able to present the outcome (numbers!) of the production implementation in the reasonable future. Leave us a comment if you want to know anything more – we’ll answer right away or put more extensive materials in a later article.