





I work on backend part of Schibsted Publishing Platform – Creation Suite, which is content management system for a number of different newspapers. It contains tools and functions that help journalists to do their jobs.
The system consists of several dozen microservices, communicating asynchronously with the use of AWS. Yes, we have these diagrams full of rectangles and a web of arrows connecting them. On the occasion of some refactoring I decided to make an inventory of the basic concepts (not so new but still worth of having in mind) in the context of messaging and our architecture. And because I believe that semantics and intentions are equally important, I will focus here on role models, making only loose inclusions that refer to the system in which I work.
Pipeline Processing

In different scenarios, a single message may require triggering a sequence of processing steps. Using the Messaging advantages, we can use the architectural pattern of Pipes and Filters, which will allow us for independent and parallel processing. Every single step of processing (Filter) becomes then a separate component, service – in the world of microservices. Each one receives the message, processes it and publishes the result to the outbound Pipe – a Message Channel. In this way, while maintaining a common abstract interface, the components can be combined freely.
Of course, this style also has its drawbacks. Each chain is as strong as its weakest link. Throughput can be improved by implementing many parallel process instances. Messaging patterns allow to extend the general pattern of Pipes and Filters about the possibility of consuming messages from, and publishing the output messages to – MULTIPLE channels. And here the mechanisms for routing messages come into play.
It is good to remember, that in the messaging world, passing messages through a chain of components is always overhead.
– In our publishing platform, we can actually talk about publishing pipeline, whose components play different roles in the processing of the article.
Message Routing
 A Message Router allows you to consume a message from ONE channel but to publish to different ONES, based on a set of conditions. The key is that it does not modify the message in any way. Its task is only to identify message destination.
A Message Router allows you to consume a message from ONE channel but to publish to different ONES, based on a set of conditions. The key is that it does not modify the message in any way. Its task is only to identify message destination.
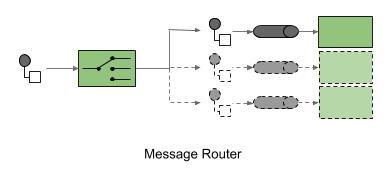
You need to be aware of a few things before you want to use the router:
- it has knowledge of all possible destinations, which can cause the maintenance bottleneck due to the large number or frequent changes of destinations
- because it is an additional component in the processing, and with a message that is essentially unchanging between the input and the output, it can introduce unnecessary overhead affecting the latency of the system
- in the end, routers can exacerbate the problem of understanding the “big picture” of the solution
CONTENT-BASED ROUTER
Sometimes we may need a solution that will allow us to handle the case that the business function is split between different systems, and that we need to ensure that the message goes to a specific one.
A Content-Based Router, as the name suggests, allows messages to be routed based on their content. This may be based on the existence of certain message fields or their values.
MESSAGE FILTER
 A Message Filter is a special type of Content-Based Router. It checks the message and routes it to the output channel when it matches certain criteria. However, otherwise the message is completely discarded. That’s the way for a component to avoid processing uninteresting messages and to eliminate them from a channel.
A Message Filter is a special type of Content-Based Router. It checks the message and routes it to the output channel when it matches certain criteria. However, otherwise the message is completely discarded. That’s the way for a component to avoid processing uninteresting messages and to eliminate them from a channel.
Thanks to the use of Message Filter, we can send messages to all components, and they filter out unwanted ones. Such a solution can eliminate the need for a Content-Based Router, but it must be remembered that entering such logic into a component means introducing dependencies into it, and that the solution is ultimately less efficient. Some solution also could be to use the Return Address.
 In some cases, we may be interested in defining the list of recipients. A typical example are e-mail recipients. In another example, we may want to send a message to various selected recipients to make alternative calculations etc.
In some cases, we may be interested in defining the list of recipients. A typical example are e-mail recipients. In another example, we may want to send a message to various selected recipients to make alternative calculations etc.
A Recipient List is an extension of two previous solutions. Attaching a list of dedicated recipients to the message allows to filter out messages by checking if the recipient is on the list.
The solution is to define the channel for each recipient. Then, based on the Recipient List, we determine the list of channels to which we forward the message.

The list of recipients (in the above case [A,B,D]) might be attached to the message itself or might be computed in the component based on the message.
Message Consumers
Application connects to a messaging system, so that it could send and receive messages, through a Message Endpoint. Here I will focus on receiving messages and patterns applied to that – Message Consumers. It’s easy to notice that they correspond to the previously described routing patterns, with the difference that now we won’t care about passing a message to the output channel, but instead focus on picking up a message and its processing.
 A Polling Consumer is an object in the receiver component that uses polling – explicitly requesting message by checking the channel to see if there is some available. Then it processes it and polls for another. So the processing time influences receiving cause it blocks until then.
A Polling Consumer is an object in the receiver component that uses polling – explicitly requesting message by checking the channel to see if there is some available. Then it processes it and polls for another. So the processing time influences receiving cause it blocks until then.
 – This is how to deal with SQS. What important to notice is that SQS: – allows receiving a number of messages at the same time; – it provides different mechanism for so called Short and Long Polling; – it requires the message to be explicitly acknowledged after processing, meaning deleted from the queue.
– This is how to deal with SQS. What important to notice is that SQS: – allows receiving a number of messages at the same time; – it provides different mechanism for so called Short and Long Polling; – it requires the message to be explicitly acknowledged after processing, meaning deleted from the queue.
COMPETING CONSUMERS
Competing Consumers are the solution for fast processing of multiple messages concurrently. So instead of having one, we can have multiple consumers listening to the same channel. Of course the solution works only with single Point-To-Point Channel (in Publish-Subscribe all consumers would get the copy of a message). Each of Competing Consumer runs in its own thread and, in effect, consumers “compete” with each other to receive the message.
This is how we can scale up consuming SQS messages by providing different number of receiver instances to consume messages concurrently. So, how long it takes consumer to process a message is no more an blocking issue here. On the other hand, this must be used carefully if consistency and isolation of message processing is a must (obvious case are other storages than the messaging system itself or distributed transactions). Otherwise, if the requirement is just very fast delivery of messages to a very large number of recipients, then such consumers might be also combined with the Message Router that routes a message to a “partition” channel that the group of Competing Consumers subscribe to.
SELECTIVE CONSUMER
A Selective Consumer allows to filter incoming messages and process only those that match certain criteria. Matching is done based on, so called, selection value – some agreed message field. So a message producer is involved in that way that before sending a message it sets that selection value. When used with Point-to-Point Channel, the challenge is to design it in that way that unmatched message would not clutter the channel.
With Publish-Subscribe, the messaging system can just discard a message even if subscriber ignored it; or the system actually could even not to send it to the subscriber filtering the messages on its own. The Selective Consumer can be used to reduce the number of used channels making just one single to act as multiple ones. This however has got some drawbacks and might not be a good idea in some cases.
A Message Dispatcher allows to coordinate work of message processing between consumers – performers. It consists of two parts:
- dispatcher – the object that consumes a message and distributes it
- performer – the object that processes a message
The performers typically run in the same application that the Dispatcher. Those could be newly created or selected from a pool; could run on its own threads; could be appropriate for each message or specialised. The dispatcher acts only as a matchmaker matching a message with a performer. The messaging system itself (like some provided Selective Consumer), may not support selection based on values of the message body. That’s where the Dispatcher comes into play. It allows us to implement more complicated selection logic, to coordinate processing, but also to fulfil a need for default case handling. Here some other known patterns, involving Handlers, coming to mind, where a message itself becomes the actual handle.
SNS Filtering
 – Of course, the best way to send a copy of a message to certain receivers is to use Publish-Subscribe Channel. Recipient subscription is then based on a specific channel or subject of a message. Anyway, it might not be always enough. SNS filtering policy allows us to apply some filtering rules to incoming messages based on its metadata and forward them to certain subscribers (in our case multiple SQS). However, there are places that require more sophisticated routing logic. So yes, in our publishing platform we still make use of message filters, content-based routers, return address, recipient list and message dispatchers additionally.
– Of course, the best way to send a copy of a message to certain receivers is to use Publish-Subscribe Channel. Recipient subscription is then based on a specific channel or subject of a message. Anyway, it might not be always enough. SNS filtering policy allows us to apply some filtering rules to incoming messages based on its metadata and forward them to certain subscribers (in our case multiple SQS). However, there are places that require more sophisticated routing logic. So yes, in our publishing platform we still make use of message filters, content-based routers, return address, recipient list and message dispatchers additionally.
Summary
I’ve just described some number of solutions that we consider or use internally in our publishing platform. Of course, the matter is much bigger and there are much more patterns in that area. I encourage you to familiarise with them, combine them and be back to them each time you face some issue in your messaging system. I would highly recommend the book, even if it is “old” and nowadays some limitations of existing solutions are reduced: Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions.
In the next article, I show some example implementation of all above with the help of SNS and SQS.